Meeting HSF1 in Antigravity 2.0 — the first chapter shipped
Beat 1 reframed this project: the molecular-heat story is the one I should have told at the I/O hackathon and didn't, because shipping any claim about human biology under a hackathon deadline is asking for trouble. Two days later I started the repo properly. This post is what happened when the project hit its first chapter — a real protein, rendered from a real structure file, with real citations, sourced live from public databases through Google DeepMind's Science Skills bundle in Antigravity 2.0. The chapter is live at heat-protein-lab.pages.dev/#chapter-1. The protein is HSF1 — the cellular thermometer.
Why HSF1 to start? Because the body's response to heat is ultimately a transcriptional response, and HSF1 is the switch that fires it. If a single protein deserves the first chapter of an explainer about heat-shock biology, this is the one. The reader meets it before they meet the heat-shock proteins it activates, because otherwise the narrative starts in the middle.
 Chapter 1, rendered. The structure is the same
Chapter 1, rendered. The structure is the same .cif.gz you would download from RCSB if you queried for 5D5U yourself; the citation accordion lists the same PubMed papers; the tissue expression is the same Human Protein Atlas IHC consensus. Just composed into reading flow.
Three things from the build were worth a post on their own.
A scientific correction caught by the verification step
The chapter’s hero protein is HSF1, the transcription factor that senses heat and switches on the genes that make HSP70 and HSP90. The design document I'd written before any code went in listed “PDB 5D5W or 5D5U” as the candidate human HSF1 structure to render in the 3D viewer.
The first thing the Phase 1 fetcher did was query the pdb_database
skill for metadata on both. The result took thirty seconds:
- 5D5U — “Crystal structure of human Hsf1 with HSE DNA”, X-ray diffraction, 2.91 Å, Homo sapiens. The right answer.
- 5D5W — Chaetomium thermophilum Skn7 with HSE DNA. A fungal homolog, not human HSF1. Wrong taxon entirely.
I had written down a structure that wouldn't have been wrong if you only read the abstract carelessly (the gene family is conserved across kingdoms; both proteins bind the same DNA motif), but it absolutely would have been wrong rendered as “your cells contain this.” A short PDB metadata query caught it in seconds, before any code or any narrative depended on it.
This happened twice on the same day. The Chapter 2 design draft listed PDB 2CG9 as the human HSP90 candidate; the same kind of query showed 2CG9 is yeast (Saccharomyces cerevisiae), and the right human structure is 7L7J, a cryo-EM Hsp90:p23 complex at 3.1 Å. Two non-human candidates caught by the same one-line verification pattern in twelve hours of work.
The pattern is small but the conclusion isn't: when a design document picks anchor data, it is worth running a thirty-second verification query against that data's authoritative source before any rendering code is written. The wrong protein at the wrong species is the kind of mistake that, once it shows up rendered with a citation underneath it, is much harder to detect.
The build pattern
 The same chapter on mobile. The three-column shell collapses cleanly: marginalia stacks on top, body next, figure last. The temperature strip and Plate badge stay anchored on every viewport.
The same chapter on mobile. The three-column shell collapses cleanly: marginalia stacks on top, body next, figure last. The temperature strip and Plate badge stay anchored on every viewport.
The Chapter 1 page is plain HTML, plain CSS, one ES module of JavaScript, and no bundler. No React, no Tailwind, no Vite. The full file count for this chapter:
index.html— the document, with a<section data-chapter="1">block holding marginalia + body + a 3Dmol viewer containersrc/styles.css— the design tokens (cream paper, Spectral serif, IBM Plex Mono labels, a heat-ramp accent system from slate at 37 °C through terra-cotta at 41 °C)src/main.js— an ES module that fetches the chapter's data files, mounts the 3Dmol viewer, hides the loading overlay, and wires anIntersectionObserverfor the chapter-aware temperature strip pinned at the top of the viewport
That's it. The structure is committed in tree at
data/structures/pdb/hsf1/pdb_00005d5u.cif.gz (74 KB gzipped), and at
runtime the JS does this:
const buf = await (await fetch(url)).arrayBuffer();
const view = new Uint8Array(buf);
if (view[0] === 0x1f && view[1] === 0x8b) {
const ds = new DecompressionStream("gzip");
const stream = new Blob([buf]).stream().pipeThrough(ds);
cifText = await new Response(stream).text();
}
viewer.addModel(cifText, "cif");
DecompressionStream is in every modern browser and means the
repo can hold the file gzipped (a quarter of the uncompressed size)
without a build step. The magic-byte check (0x1f 0x8b) makes the
code robust to whether the dev server adds a Content-Encoding: gzip
header. Python's http.server doesn't.
The sticky figure trick is also worth flagging. On screens 1024 px
wide and up, the figure column gets position: sticky; top: var(--temp-strip-height) + 32px; align-self: start;,
so the spinning HSF1 ribbon stays glued to the same screen position
while the reader scrolls through the chapter's body text. The
protein is in view the entire time it's being discussed. It is
the single biggest readability improvement I made in the chapter, and
it is four lines of CSS.
The agy CLI stall, and what it told me about prompts
Beat 1 mentioned the “specific small prompts beat orchestration prompts” rule in passing. Chapter 1's build made me believe it.
The Phase 1 data layer required four fetches: PDB structure file,
AlphaFold structure file, top-three PubMed papers on HSF1
trimerization, and Human Protein Atlas tissue expression. Asking agy
--print to do all four in one prompt produced the exact same 0.0%-CPU
stall I'd hit during Phase 0. PID alive, one open network socket,
no uv subprocesses spawned, no output for fifteen minutes. The
agent was stuck in its planning step.
The pivot that worked: write a small project Python script
(scripts/01_hsf1.py, hundred lines) that shells out to the canonical
skill CLIs at their plugin path:
PUBMED_SCRIPTS = Path.home() / ".gemini/config/plugins/science/skills/pubmed_database/scripts"
run([
"uv", "run", str(PUBMED_SCRIPTS / "pubmed_api.py"),
str(search_path), "search_pubmed",
"heat shock factor 1 HSF1 trimerization activation",
"--max_results", "5",
])
It ran end-to-end in under a minute. PDB and AlphaFold were already
cached from Phase 0's smoke tests; PubMed returned three real
papers (PMIDs 30467350, 33493517, 27354066); HPA resolved HSF1 to
ENSG00000185122 and reported tissue expression across forty-nine
tissues. The same Human Protein Atlas fetch that stalled under
agy --print returned a 4.5 KB JSON in seconds when called as a
subprocess.run. Same skill, same arguments, two invocation paths,
very different reliability.
The rule that came out of it: when you can write down the exact shell command, write it down; don't make the IDE plan it for you. The IDE's value is between commands, not in choosing them.
What rendered
Chapter 1 on the page now shows the marginalia column with a tissue- expression badge sourced from live Human Protein Atlas data (“Expressed across 49 of 49 tissues; high in adrenal gland, breast, bronchus, cerebellum (+20 more)”), a 64-character-wide reading column with body copy that introduces HSF1, an inline 3Dmol viewer rendering the actual 5D5U mmCIF with the protein chains in ochre cartoon and the HSE DNA strands in slate, a citation accordion exposing the three PubMed papers above with author lists and PMIDs linked out to NCBI, and a small AlphaFold-derived note about HSF1's global pLDDT of 61.31 confirming the protein is partly disordered by design.
The PDB overlay at the bottom-left of the viewer is a real link to RCSB's 5D5U entry. The PubMed citations are real PubMed entries (the Neuroprotection by HSF1 paper in Scientific Reports, the SUMOylation paper in JBC, the p38 MAPK substrate paper in MCB). The HPA tissue claim is sourced from the live IHC consensus and re-fetchable by running the project script in tree.
Three sharp edges worth lifting
For anyone setting up a similar workspace:
scripts/generate_*.pyfiles Antigravity writes need to be in.gitignorefrom day one. The IDE auto-generates Python clients that embed API keys inline. We caught two before commit on the same day and the gitignore patterns at the project's.gitignorecatch the family of file names the IDE chooses (mostlymcp_client.py,generate_*.py,*_client.py).- The science-skills plugin has three upstream bugs as of v1.0.0
worth filing if you hit them: AlphaFold returns HTTP 403 without
SCIENCE_SKILLS_USER_AGENTset; HPAhpa_cli.py get-tissue-expressionraises aValueErrorand needs a separate HTTP client for its XML endpoint; the Reactome diagram'sAcceptheader for SVG needed a one-character fix. All three patched locally on my Pi; the drafts are in tree atnotes/devrel/upstream-issues/and filed againstgoogle-deepmind/science-skillsas issues #2, #3, and #4. - The IDE's desktop and CLI modes behave very differently.
Antigravity Desktop ran a nine-Stitch-screen mockup generation in
parallel via Python
threadingfrom a single prompt and converged in two minutes. The CLI's--printmode on the same machine, same plugin, stalled forever on a six-skill orchestration prompt. Don't generalise from one to the other.
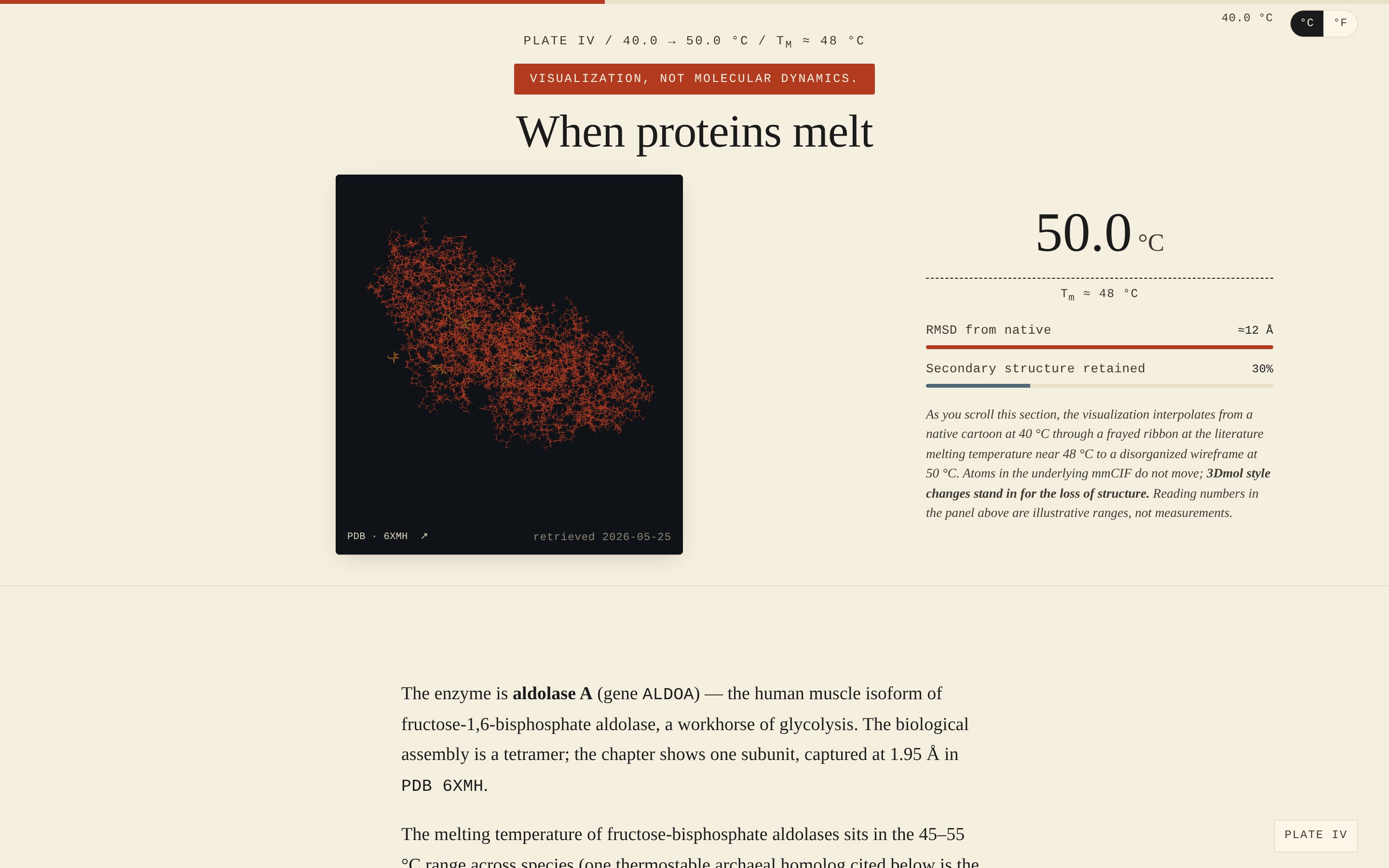 Chapter 4. The visual centerpiece — and the next post. The 3D structure is a real
Chapter 4. The visual centerpiece — and the next post. The 3D structure is a real .cif.gz of human aldolase A; the visualization interpolates the rendering style from native cartoon through frayed ribbon to disorganized wireframe as the reader scrolls. The atoms don’t move (that would require molecular dynamics, which I don’t have and don’t claim); the style transitions stand in for the loss of structure. The disclaimer rides at the top of the chapter for the whole stack.
 Mid-session add: a Celsius / Fahrenheit toggle. The page chrome, the chapter eyebrows, the Ch 4 scroll-driven readout, and the Ch 8 toy-WBGT bridge all switch at once. The toy model still runs in °C internally; only the labels translate. Choice persists in localStorage. Took roughly twenty minutes — most of which was deciding what NOT to convert in the prose.
Mid-session add: a Celsius / Fahrenheit toggle. The page chrome, the chapter eyebrows, the Ch 4 scroll-driven readout, and the Ch 8 toy-WBGT bridge all switch at once. The toy model still runs in °C internally; only the labels translate. Choice persists in localStorage. Took roughly twenty minutes — most of which was deciding what NOT to convert in the prose.
What's next
The chapter is the first of nine sections on the page. Chapters 2
through 8 follow the same pattern: marginalia + reading body + a
figure column with a 3Dmol viewer or schematic or heatmap or chart,
all reading from data files committed to data/. Chapter 4 is the
visual centerpiece, scroll-driven, and is the trigger for the next
post (Beat 3).
The repo is at HeatThreshold/heat-protein-lab, MIT-licensed, no medical claims, no analytics. If you're working in the same space, the issue templates ask the questions I'd want asked.